But let’s get to the topic this post is actually about: This week’s MakeoverMonday!
Since it is TC20 week, there was also a special Live MakeoverMonday. I managed to join the Monday evening session on Youtube.
So what was different this week? Well, the idea is the same. But the topic was introduced on the livestream and we then had an hour to work with the dataset and submit our viz. After that, the MakeoverMonday team took some time to review some of the results on the livestream. So the big difference for me this week was timeboxing.
I usually don’t limit the time I work on my MakeoverMonday viz. And it often takes me quite a while. Typically it’s not because I lack the technical skills (though that happens too, of course). I typically have a hard time settling on an idea and tend to overthink things. But getting things done quickly is an important skill. So this was an interesting and exciting exercise for me!
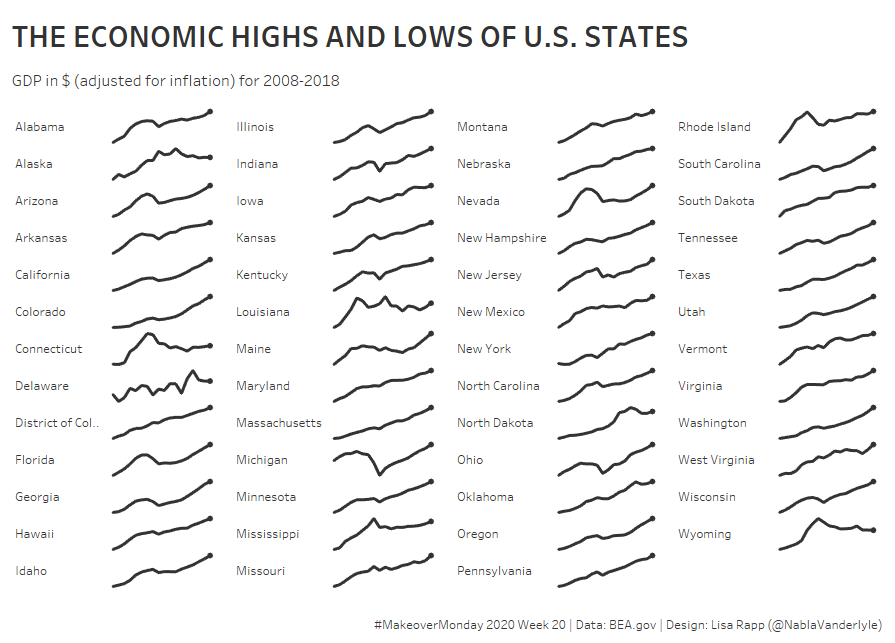
So here’s what I ended up with after an hour: